
Get OCR Text Activity Examples in UiPath
Just Dial is an online search engine that hosts thousands of services, sellers, dealers, shops, and owners who publish their information to connect better with customers and other businesses. This website uses a lot of features that do not allow us to scrap the website easily.
They use image-based phone numbers, as a result, the information is not stored inside a webpage element. We need to use OCR technology to read the numbers from the image. This tutorial will focus on overcoming these issues and scraping the available information into the desired format.
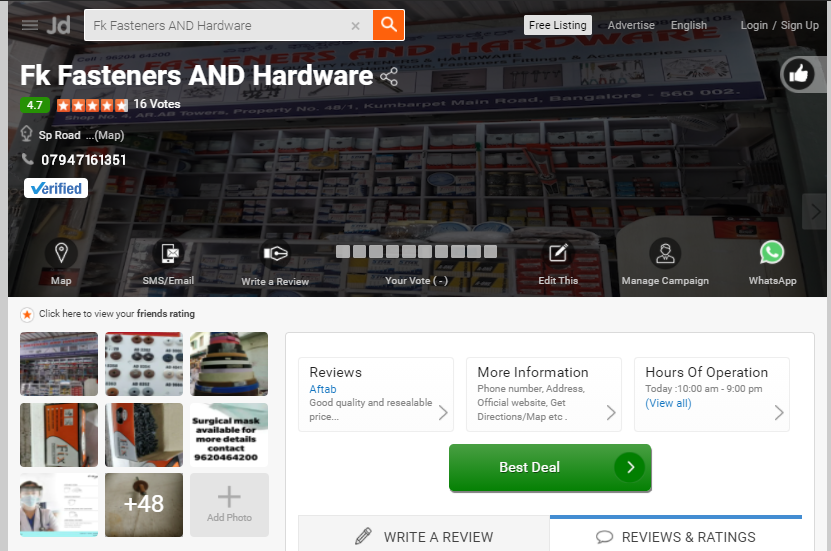
This is how a basic just dial page looks like. The dealer/manufacturer name, address, and even the images can be scraped very easily. However, the phone numbers are displayed in an image format, and hence Get Text does not work.
In the above image, “07947161351” has 11 images stitched together to form the final image. Therefore, each digit is associated with a different image. To solve this problem, we will use Get OCR Text, which will use Tesseract OCR technology to read the information from the website.
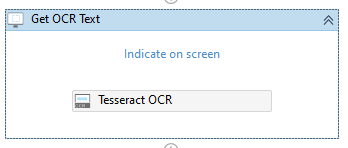
- Clicking on "Indicate on-screen" redirects the user to select the element to be extracted.

- Upon successfully selecting the element containing the phone number, UiPath will map the selectors and assign it to the Get OCR Text activity.
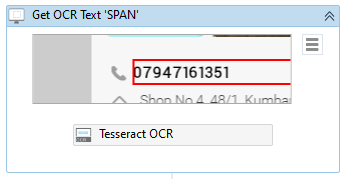
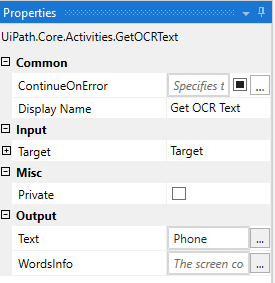
- We will save the output to a string variable, Phone using the Properties panel.
- Finally, the extracted text will be written in the Output Panel using the Write Line activity
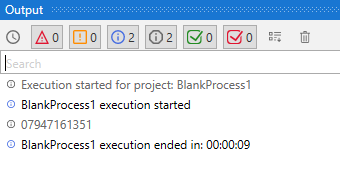
- On executing the sequence, UiPath is able to grab the information and print it on the Output Screen as evident from the image
It is important to note that, Get OCR Text only works when the image is visible on the user’s screen. If the element is hidden, it requires to be scrolled up. OCR fails to recognize the information within the element when it is not visible.