
Introduction:
In this post, we are going to be looking at which Python library is best suited for OCR. Python, as you may already know, is a programming language that is used to create digital tools and software. It can also be used to create OCR tools—which include software that can perform image-to-text conversions, PDF-to-Word conversions, and so forth.
What is OCR?
OCR stands for Optical Character Recognition. It is the name of the technology that allows a software/machine to recognize characters and letters written non-digitally (like on a paper or whiteboard, etc.) or in a non-editable format (such as a PDF file.)
With this technology, the text written in the above-mentioned ways can be extracted, copied, edited, and saved as digital text.

Which Python Library is Best Suited for OCR?
Before we get to discussing which Python library is best suited for OCR, there are some fundamental elements that we need to discuss first.
Essentially, one of the best Python libraries that you can use for OCR is Pytesseract. But to understand Pytesseract properly, we first need to understand Tesseract itself.
What is Tesseract?
Tesseract is an open-source OCR engine that was initially started by HP (Hewlett-Packard) but later acquired by Google.
As an open-source OCR engine, Tesseract can be used by anyone for free. It can be used to convert images and PDF files into text.
The engine works as an API. In other words, it can be used by creating an API integration where you can send a request to the engine using an application/software and submit an image or PDF file.
Nowadays, Tesseract has improved its functionality by integrating AI into its working that allows it to convert characters/text in images more accurately.
What is Pytesseract?
Moving on, let’s take a look at what Pytesseract is.
If you look at the word, you’ll see that it is just two words put together: “Py” and “Tesseract.”
The “Py” here refers to “Python.”
Pytesseract is basically a wrapper or a “skin” for Google’s OCR engine that makes it easier for users to utilize the image-to-text functionality directly using Python code. Tesseract itself is an engine, but with Pytesseract, it becomes usable in the form of Python. That is the simplest definition that we can provide for it.
How to use Pytesseract?
Using Pytesseract for image-to-text conversion is quite easy and simple.
To get started, you must first download the Tesseract OCR engine to your computer as well as the Pytesseract library and OpenCV library.
Once you are done with these prerequisites, here are the steps that you need to take.
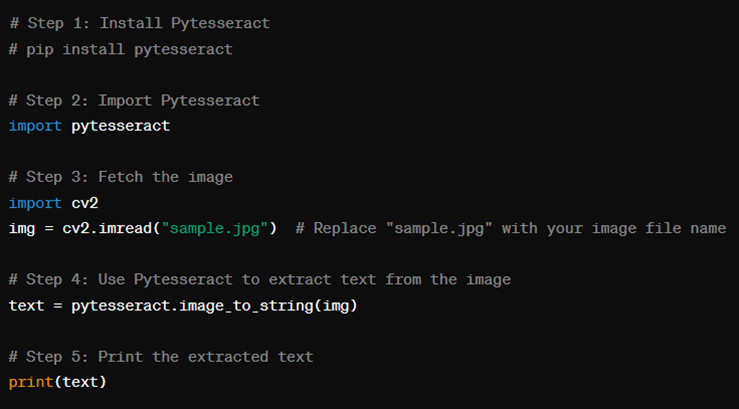
1. First of all, install the Pytesseract library. To do that, you have to use the command “pip install Pytesseract” without the quotes
2. Then, in order to start using the Pytesseract library, you have to import it into your current Python script. You can do this by using the command "import pytesseract” without the quotes
3. The next step in the process is to fetch the image that you want to convert to text. For that, you first have to import the OpenCV library using the command “pip install opencv-python.”
4. Then, you have to use this command “img = cv2.imread(“sample.jpg”)” without the outer quotes. In place of the “sample.jpg,” you have to input the name of the actual image. (This applies if the image is in the same location/directory as the Python script file. If the image is in another location on your computer, you have to specify the whole route.)
5. After this step comes the part where you actually use the Pytesseract function. You have to enter the command “text = pytesseract.image_to_string(img)” without the quotes
6. Once you are done with the above, the image will be converted to text using the Tesseract engine. The extracted text will be stored in the variable "text" that you used in the last command. You can then print the text using the command "print(text)” without the quotes.
Below, you can see an image showing the whole code in the correct sequence. The gray pieces of text are just comments for your edification. You can leave them when running the code yourself.
Other ways to use OCR
And with that, our guide to Tesseract and Pytesseract comes to an end.
We have shown the exact commands that you can enter to use the image-to-text extraction function of Tesseract using the Python library. However, there are some limitations to this process.
For one, a person with 0 programming knowledge may find it difficult to download and import the engine and the library. They could also struggle with entering the commands properly and executing the process.
In situations like this, image-to-text conversion can be done in other easier ways.
·You can convert image-to-text using an online web-based tool. There are tools available on the Internet that you can find with a simple search. These tools allow you to input an image and get the output in text form.
·You can also do the same thing with the help of downloadable mobile applications. To do that, you can simply visit the application store on your mobile, such as Google Play on Android phones, and then download an image-to-text converter.
Conclusion
Converting images to text is something that can be required quite often nowadays. Data entry, data storage, etc., are all made easy with the help of image-to-text conversion. In the post above, we’ve looked at how you can do that using the Tesseract OCR engine, and the Pytesseract library in specific.
For people who want to perform the process quickly, there are easier solutions available, such as online tools and mobile applications.
Comments (0)