
Extracting Emails and Phone Numbers from PDF Using UiPath RPA
In this tutorial, we will learn how to use UiPath to extract data from PDF. PDF stands for Portable Document Format and is used primarily to share information. UiPath does not have any pre-installed activities that allow a user to work with PDFs. We need to add PDF activities using the Manage Packages option.
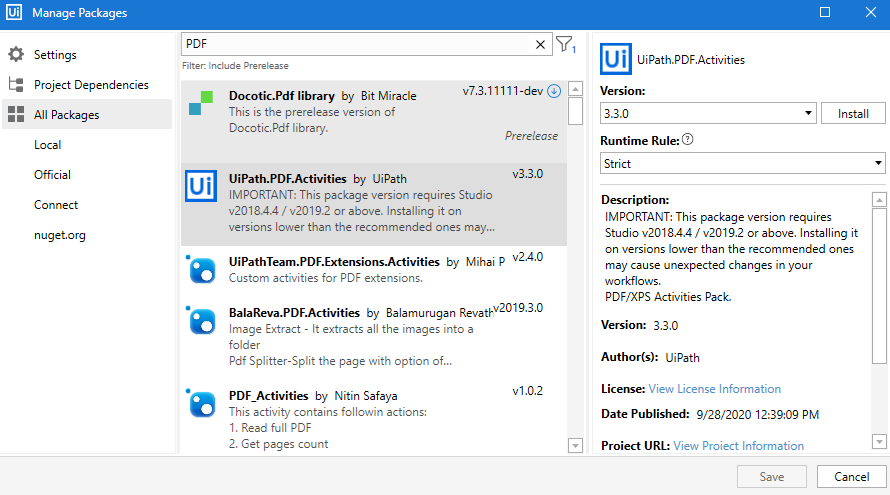
- Search for PDF under the All Packages option and it should bring up UiPath.PDF.Activities package. Click on it and select Install. Once installed, click on save to finalize the setting.
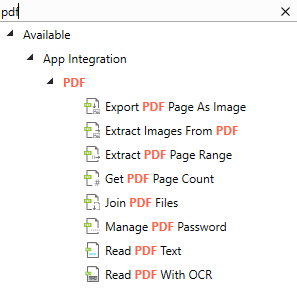
- Once the PDF package is successfully installed, search for PDF in Activities Panel and it should bring up the following results
Export PDF Page As Image
Using this activity, a user can extract a specific page from a PDF into an image file (PNG). The Image Dpi can be adjusted using the Properties Panel.
Extract Images From PDF
Users can easily extract all images from a PDF using this activity. All image files will be saved in PNG format and the user requires to input the output folder in the Properties Panel.
Extract PDF Page Range
This helps to read pages from a PDF up to a specific page limit as defined by the user and extract those pages as a separate PDF file.
Get PDF Page Count
Checks the number of pages in a PDF and saves it into an Int32 variable.
Join PDF Files
The user can merge two PDF files using this activity.
Manage PDF Password
It helps to change the existing password of a PDF and create a new PDF file with a new password.
Read PDF Text
The most important activity that reads all text information inside a PDF and can be saved inside a string variable. Various operations can be performed on this string variable to extract data as per requirements.
Read PDF with OCR
Similar to Read PDF Text but this one uses the OCR technology and hence not 100% accurate. This is useful on very special occasions where the text information is unclear or scanned physically.
Extracting emails and phone numbers from PDF

For this tutorial, we will use an attendee list that contains three emails and phone numbers as shown in the image. The same procedure will also work for extracting N number of emails or phone numbers from any PDF document.
- First, we will use the Read PDF Text activity and input the location of the PDF.
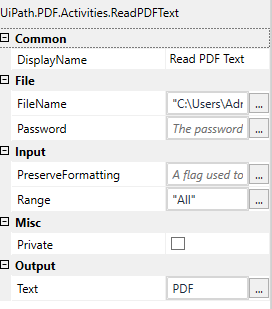
- The output will be saved inside a string variable named PDF.

- To extract emails from this text information we need to use the Matches activity that uses advanced RegEx patterns to identify the emails.
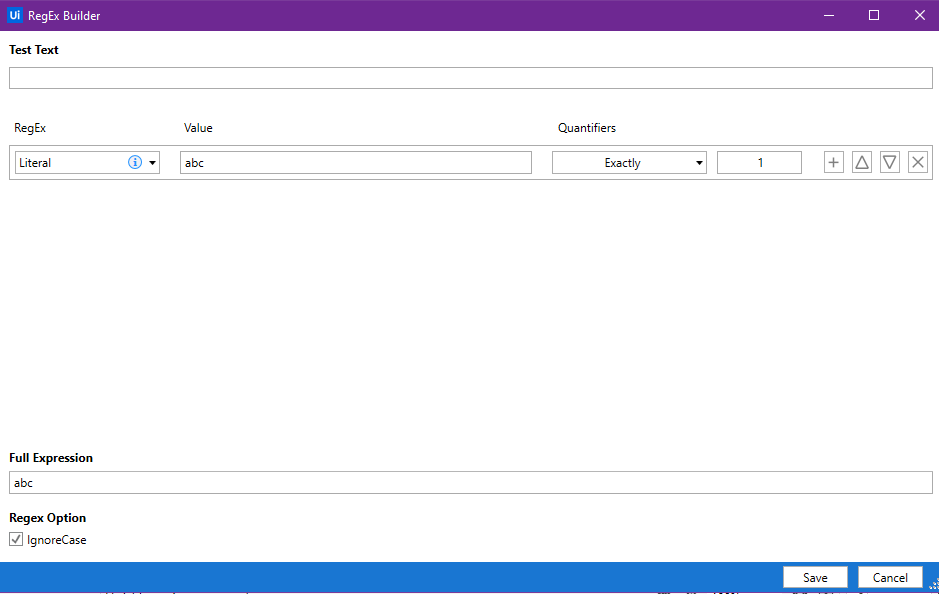
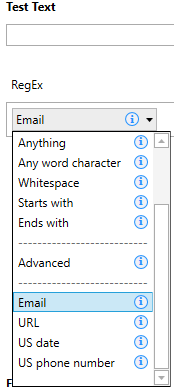
- Click on Configure Regular Expression which will bring up the RegEx Builder dialog box.
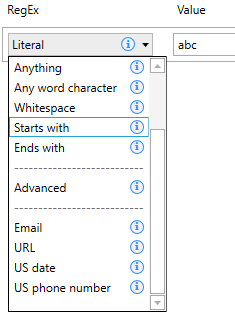
- On the left hand click on, click on the RegEx box and select Email. This is an inbuilt Email RegEx provided by UiPath. It is important to note that hundreds of RegEx for extracting emails are available all over the internet and can be used as well.

- For example, https://www.regular-expressions.info/email.html is a good site for finding RegEx for almost any requirements. To use RegEx acquired from the internet, the user needs to select Advanced from the drop-down menu and paste the RegEx inside the Value box. Finally, click on save and this finalizes the settings.
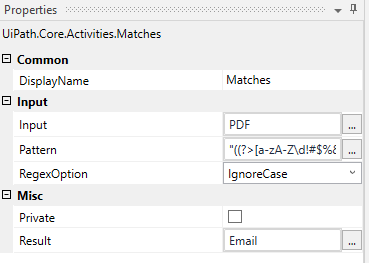
- Inside the Properties Panel, we have supplied the PDF string variable as input and created a new Enum variable Email where the output will be saved.
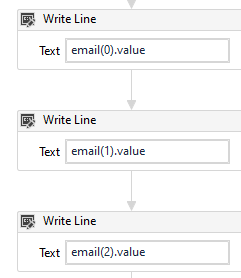
It is important to understand that Enum variables store the extracted information in the form of arrays. As there could be multiple results as per the RegEx pattern, each result is stored starting from 0 to 1, 2, and so on. In our case, we will find three values and hence we will directly assign 0,1,2 along with the Email Enum variable as shown in the image. The .Value syntax converts the Enum variable into a string variable.
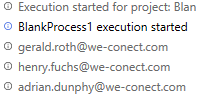
- On executing the workflow, the Output Panel shows the three emails we have been looking for.
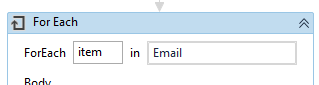
- However, in many cases the number of emails associated with a PDF is unknown, and hence in those cases, we need to use For Each activity.
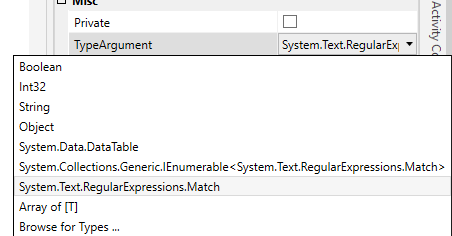
- In the Properties Panel, we need to change the TypeArgument to System.Text.RegularExpressions.Match to align with the variable type of Email.
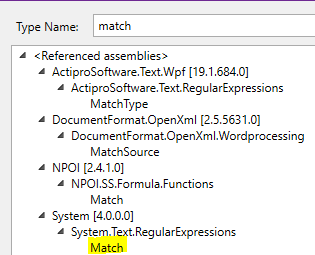
- The variable requires to be found using the Browse for Types option.
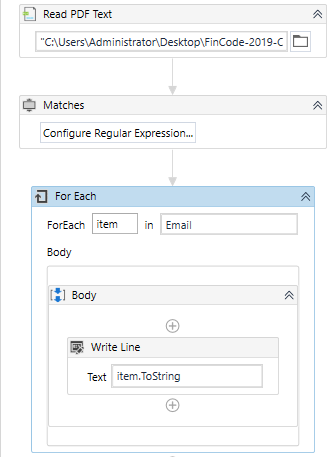
· The final workflow should look like this. We are using item.ToString to convert the Enum value into a string variable and is necessary for the workflow to execute without validation errors. On executing the workflow, the final output is shown in the image below.
- To extract phone numbers, we will use the same concept but alter the RegEx pattern inside the Matches activity.
- Unlike emails, phone number formats vary country wise, and hence each country number requires a specific RegEx, and the US phone number pattern provided by UiPath may not work universally. The user can simply look for RegEx patterns for their own country or make one of their own if necessary.
- The phone numbers included in the PDF do not follow an US pattern and hence we will customize the RegEx pattern with (\(?([\d \-\)\–\+\/\(]+)\)?([ .\-–\/]?)([\d]+))
- We have created a new Matches activity and supplied a custom RegEx pattern. The results will be saved inside the Phone Enum variable. The final output of the workflow sequence is highlighted in the image above.
Depending on the type of information that requires to be extracted, various RegEx patterns can be used which can be user made or taken from the internet. The same workflow will work for any type of data to be extracted but only requires the user to change the RegEx patterns.